What Are Indexed Web Pages
-

Aaron Gray
- Blogs
-

 March 29 , 2022
March 29 , 2022 -
 7 min read
7 min read
Are you wasting your time?
Spending hours creating new web pages, blogs, case studies, and more only matters if your pages are getting indexed. If search engines like Google don’t index your website, you’re basically shouting into an empty void.

You need your audience to hear your message, and the best way to do that is to get your website indexed by Google.
What is Google Indexing?
To set the stage for our discussion on Google indexing, let’s discuss some important terms: crawling, Google bots, Google indexing, web spider, and ranking.
- Search Engine Crawling is a process that search engine bots complete by scanning webpages and extracting data.
- Google bots are Google’s search engine bots that crawl and index web pages.
- Google Indexing is Google’s process of crawling and cataloging websites to be displayed on search engine results pages or SERPs.
- Web spider is another name for search engine bot
- Ranking, which is not the same as indexing, refers to how search results are organized on SERPs based on a variety of factors that help determine which content is most or least relevant to the search query.
Essentially the Google index is one massive repository that uses bots to crawl websites and collect data in an attempt to catalogue all content on the internet. I say attempt because not all websites or webpages are part of Google’s index or any search engine index, and that’s not necessarily a bad thing.
It’s important to note that other search engines also have their own search engine bots. These are just a few.
- Googlebot is for Google.
- Bingbot is for Bing
- MSNbot is for MSN
- Baidu spider is for the Chinese search engine Baidu
Let’s dig deeper into the Google index to uncover how to check if your site is indexed, how to get indexed, how to opt out of the index if some content is meant to be kept private, and how optimizing your indexing could improve your rankings.
How to Check if Your Website Has Been Indexed by Google
You can easily check if your site is indexed by Google or any other search engine by creating a search query that starts with search: or info: then add your desired URL.
For example, if we wanted to find out if our guide to tiered link-building was indexed we would go to Google and type search: https://nobsmarketplace.com/link-building/tiered-link-building/
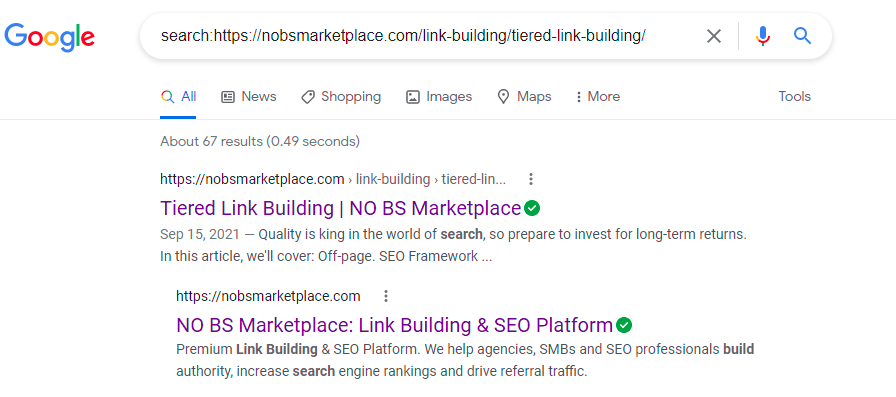
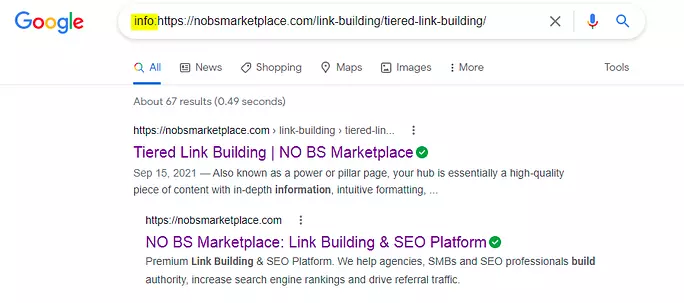
If nothing shows up in the search results, then we know the site isn’t indexed, but as you can see from the screenshot, our guide is indexed on Google. We could have done the same search with info: instead, and it would yield the same result. See the example below.
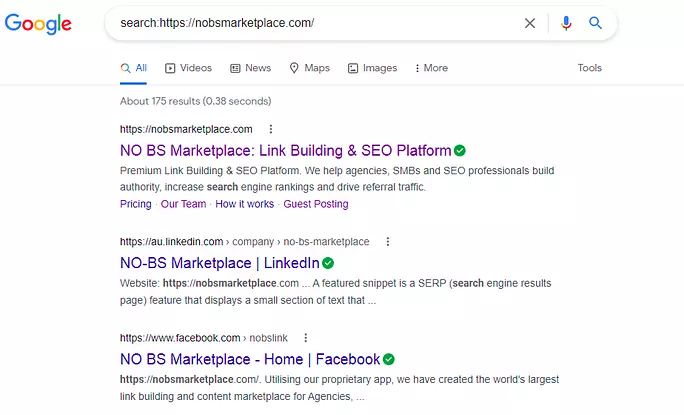
You can perform the same search for an entire domain as well to see which pages are indexed for an entire website. Here are the top three ranked pages that appeared when we searched for our domain, our website, LinkedIn profile, and Facebook page.
So, what if your site isn’t indexed? Let’s go over some simple steps you can take to join the Google index.
How to Join the Google Index
There’s no badge of honour or small prize for joining the Google index, but you do get the subtle satisfaction of your website finally being seen… potentially.
Getting indexed doesn’t guarantee a top-ranking spot on SERPs. Think of it as the first step on your SEO journey. And if you’re ready to take that first step, here are some simple things you can do to get indexed by Google.
1. Site Map
A site map is a list of pages within a website. They are important for indexing because they give search engine bots a clear picture of what is on your website. To help Google capture the most relevant content on your website, it’s important to build and update your site map regularly.
- A quick tip: before building your sitemap, organize your URLs into tiered categories such as top-level navigation, second level, and third level. Be sure to keep your URLs organized and within their appropriate categories the first time to avoid updating or changing URLs and creating broken links.
2. Robots.txt
A robots.txt file is a short text file that lives in your home directory. This file acts as a guide for web spiders during the crawling process. Within the robots.txt file, you can outline which pages can be crawled and indexed and which pages should be left out. You can learn more about robots.txt in our guide for beginners and if you need help creating a robots.txt file, check out our free robots.txt generator.
3. Internal Linking
The site map creates an outline of your website and internal links add more detail to the picture by showing what content is related, what content is referenced often, and more. They also act as a way to drive traffic from one page to another within your website, retaining the traffic from page one and passing that traffic along to page two. We discuss all of this and more in our simple guide for internal linking.
4. High-Quality Backlinks
A backlink is a link to your website from another website. You can create these links intentionally, but before you start make sure you explore themed link-building, blogger outreach best practices, and how to create a link-building strategy.
It’s also important to review your site and fix things that could be hurting your website’s ranking. Here are four easy ways to optimize the content that gets indexed for your site: removing low quality pages and no follow internal links, using or removing noindex tags and canonical tags.
5. Remove Low-Quality Pages
Low-quality content or duplicate content can negatively impact your ranking and waste valuable crawling time. Content that is thin, lacking substance, filled with ads, or all around doesn’t provide value for the reader is considered low-quality or thin content. Deleting or archiving these pages is best practice because web crawlers only have a certain amount of crawling time to spend on your page and you want that time to be used wisely for high-quality content that best represents your business.
6. Remove No Follow Internal Links
Review all internal links periodically to ensure all links are active. When new page visitors are exploring your site and are led to a broken link, they are more likely to leave your site and continue searching for what they want elsewhere. If you want to keep traffic on your site, get rid of no-follow links. Creating healthy links allows valuable traffic to flow from one page to another on your website.
7. Noindex Tags
To tell search engines which pages to avoid crawling, you can use a ‘noindex’ tag, a type of metatag that is used to customize how search engine bots crawl and index a page. You can add these tags to pages within your website’s robots.txt file. A similar tag ‘nofollow’ can be used to tell search engines not to crawl any links listed on a specific page.
8. Canonical Tags
Using canonical tags is a great way to tell Google’s search engine bots what is the master copy of a page. If you have a larger volume of duplicate content, this could be a way to optimize crawling time without having to go back and archive lots of content right away.
Conclusion
Getting indexed by Google and other search engines will take time, but as long as you are consistent and follow the steps listed above, your website’s best content will be indexed and visible on SERPs. That means more traffic and more opportunities to connect with your ideal customer.
Subscribe to Our Blog
Stay up to date with the latest marketing, sales, service tips and news.
