The Ultimate Robots.txt Guide for Beginners: Best Practices &
Examples
-

Aaron Gray
- Blogs
-

 November 01 , 2021
November 01 , 2021 -
 11 min read
11 min read
You have more power than you think when it comes to controlling how web crawlers scan and index your site. And that power lies in the robots.txt file.
In this post I will show you what a robots.txt file is, why it’s important, and how you can easily create one on your own or using our free Robots Txt Generator. You will also learn about meta robots tags, how they compare to a robots.txt file, and how both can have a big impact on SEO.
Do you know what’s in your robots.txt file?
At face value, ‘robots.txt file’ sounds like a complex coding term, but the concept is actually quite easy to understand.
A robots.txt file tells search engine bots what parts of your site to visit, crawl, and index and which parts of your site to stay away from. This is not a substitute for protecting sensitive or private information from showing up on search engine results pages or SERPs. If you need to protect sensitive or private information consider password protecting the page or block indexing.
Think of your website as a museum and the robots.txt file is the tour guide that lets you know which exhibits to visit and which places are currently off-limits to visitors.

Within the robots.txt file are directives that tell search engine bots what pages are allowed to be crawled and which pages are not allowed. A search engine bot, or web crawler, is a program that scans and indexes website information for any site on the internet. The goal is to catalogue information so that it can be retrieved by those seeking it through search engine page results.
Within the robots.txt file you can speak to all search engine bots with an asterisk (*). Which would look like this:
User-Agent: *
Or you can speak specifically to one bot, which would look like this:
User-Agent: GoogleBot
User-Agent: HaoSouSpider
After you identify which bots you’re talking to, it’s time to decide what you want to allow or disallow. To do that you simply state allow or disallow and then the desired URL. Here is an example of our robots.txt page:
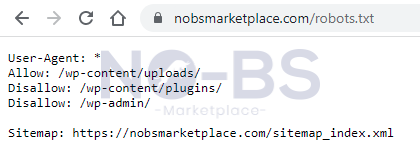
As you can see here, we’re speaking to all search engine bots because we have ‘User-Agent: *.’ You can also see that we allow all web crawlers to index www.nobsmarketplace.com/wp-content/uploads/ but we don’t allow bots to crawl the URL’s ending in /wp-content/plugins/ & /wp-admin/.
Nike, however, has a much more complex robots.txt file. Check out the example below:
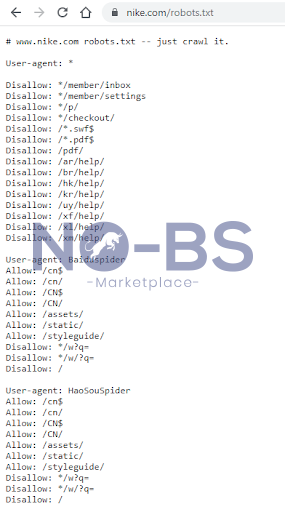
Nike speaks to all web crawlers in the first rule group and then calls out specific bots in the second and third rule groups.
Each rule group in a robots.txt file has different directives: user-agent, allow, disallow, sitemap. Nike adds a little flair to their robots.txt file at the beginning with ‘just crawl it,’ a nod to their iconic slogan ‘just do it,’ and they include a classic Nike swoosh at the end as shown below.

You don’t have to customize your robots.txt file this way for it to be effective, so don’t get discouraged. Just focus on the 4 main directives:
1. User-Agent: determines which search engine crawler this rule applies to
2. Allow: determines if the site is allowed to be crawled & indexed
3. Disallow: blocks search engine bots from crawling & indexing site info
4. Sitemap: indicates the location of the site map for a site
If you simply want to allow or disallow all parts of your site just use ‘/.’ This could look like:
User-agent: *
Allow: /
If you unknowingly have a robots.txt file that is blocking web crawlers from your site, this could really hinder your SEO efforts in the long run, so it’s best to have a solid robots.txt file sooner than later.
Understanding the massive impact your robots.txt file can have on your site.
Having a robots.txt file for your site is not necessary, so if you don’t have one, don’t worry. Sites without a robots.txt file are typically scanned and indexed normally by web crawlers. But, if you want to have more control over your SEO rankings then here are some of the benefits of having a robots.txt file for your site.
Block duplicate content: Duplicate content can hurt your search engine rankings, so ensure pages with duplicate content are off-limits to web crawlers

Crawl budget protection: Google and other search engines have an allotted crawl budget for all websites. Websites that have high authority get a higher crawl budget because they have a large amount of useful and trustworthy information. No matter the level of authority your site has, the supply of search engine crawling is limited, so having a robots.txt file in place allows web crawlers to focus on indexing quality information.

Pass along the link equity: Link equity is the value that ‘Site B’ receives when ‘Site A’ links to it. When ‘A’ gets high traffic and pushes some of that traffic to ‘B,’ then ‘B’ receives an increase in traffic and that is an example of passing along the equity. A perfectly crafted robots.txt file allows traffic to flow to pages that are valuable and restrict visibility from the less desirable pages.

Anyone can create a robots.txt file – you don’t have to call IT.
Every website can have one roebots.txt file and it lives at the root of your site. So, if your website is www.samplesite.com then your robots.txt file will live on www.samplesite.com/robots.txt/. Your robots.txt file cannot be placed in a subdirectory like www.samplesite.com/plantcare/robots.txt.
You can create a robots.txt file in any basic text editor, like Notepad for example. Word processing software is not ideal for creating this kind of file because it can add unnecessary characters when the file is saved in a proprietary format. Here are 5 things to keep in mind when creating your robots.txt file:
- Name the file robots.txt
- Ensure the file is located at the root of your site
- Create one or more rule groups
- Within the rule group add a directive
- User-agent
- Allow
- Disallow
- Sitemap
- Remember that web crawlers often crawl a page by default, so if you want to block crawling and indexing, give the disallow directive
Our free robots.txt generator makes the creative process easy.
To help you craft the perfect robots.txt file we have a free generator that you can use anytime. Simply fill in the information and a robots.txt file will be generated for you. Our free robots.txt generator is simple and easy to use
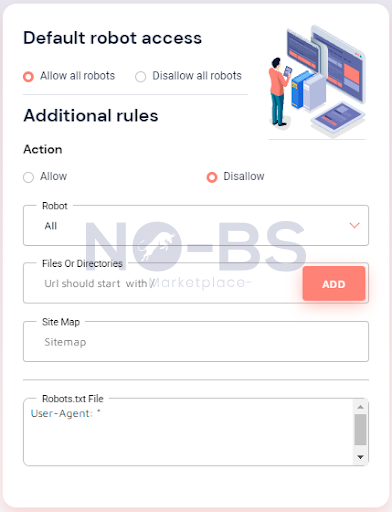
After you’ve created your robots.txt file, it’s time to upload it based on your website host’s requirements. Some website hosts, like Wix, may create the robots.txt file for you and in these instances, you won’t be able to create, edit, and upload your robots.txt file manually.
Not sure if your site has a robots.txt file? Here’s how you can check.
Your site may already have a robots.txt file and you can easily check. Simply type in your URL and add ‘/robots.txt’ and your robots.txt file should come up.
Robots.txt and meta robots tags are sisters, not twins.
Meta robots tags and a robots.txt file both give instructions to web crawlers, but meta robots tags give more specific parameters. The robots.txt file has 4 directives: User-Agent, Allow, Disallow, & Sitemap.
Meta robots tags have 10 different parameters: Noindex, Index, Follow, Nofollow, Noimageindex, None, Noarchive, Nocache, Nosnippet, Unavailable_after. Each of these parameters guides the web crawler in different ways. Let me explain.
- Noindex: You don’t want this page indexed.
- Index: You do want this page indexed. Crawling and indexation are automatic, so in most cases, you don’t need to use this.
- Follow: Pass the link equity, please! Use this parameter when you want to pass equity on to the linked pages that are not indexed.
- Nofollow: Don’t follow these links, please!
- Noimageindex: You’d rather leave the images out of it. When crawlers see this they know not to index any images on the page.
- None: You want to combine the power of Noindex and the Nofollow.
- Noarchive: You don’t want to display a cached link to this page on SERPs.
- Nocache: The Internet Explorer and Firefox version of the Noarchive tag
- Nosnippet: You don’t want a meta description for this page on SERPs.
- Unavailable_after: You want search engines to stop indexing this page after a set amount of time.
The meta robots tag lives within a web page’s HTML code in the <head> section. Here is an example of what it could look like:
<!DOCTYPE html>
<html lang=”en-US” prefix=”og: https://ogp.me/ns#”>
<head>
<meta charset=”UTF-8″>
<meta name=”robots” content=”noindex” />
In this example, by stating “robots” we are speaking to all web crawlers and by stating “noindex” we are telling them not to crawl and index this page.
If you want to specify the user-agent, you can replace “robots” with the desired user-agent, like Googlebot for example.
So, to recap, the meta robots tag lives in the HTML code of a specific web page and gives firm instructions to web crawlers. Unlike a robots.txt file that has its own separate page and speaks for the entire website, a meta robots tag just speaks for one page. Both robots.txt and meta robots tags tell search engine bots how to crawl and index your page which gives you more control over your SEO journey – if you use them wisely.
With great meta robots tags comes great responsibility.
Meta robots tags can have a huge impact on SEO just like a robots.txt file. You can use meta robots tags instead of or in conjunction with a robots.txt file.
If you use meta robots tags instead of a robots.txt file, you might miss the big picture. A robots.txt file allows you to see how you’re directing web crawlers through your site as a whole whereas the meta robots tag only affects one specific page. But on the plus side, meta robots tags allow you to be more specific about how you want web crawlers to treat each page separately making it more customizable.
If you use a robots.txt file instead of meta robots tags, you might miss small details that could cost you. While it’s great to see the forest through the trees, sometimes you need clearer, more specific directives for a page to ensure quality relevant content is displayed on SERPs and less relevant content can fade into the background.
If you choose to use meta robots tags and a robots.txt file at the same time here are some tips for success.
- Think of your robots.txt file as a tour guide for your entire site.
- Think of meta robots tags as a tour guide for a specific page on your site.
- Both robots.txt files & meta robots tags are crawled by search engine bots and both have equal authority.
- Be consistent! Minimize contradictions between the robots.txt file and meta robots tags.
SEO success with meta robots tags & a robots.txt file
- Create quality content. Ensure your content is engaging, trustworthy, and builds your authority. Robots.txt files & robots meta tags are there to tell web crawlers where to go. The less you have to hide, the better.
- Don’t duplicate content. If you have duplicate content on your site make sure to hide any duplicates using robots.txt or meta robots tags. Duplicate content can damage your SEO score and lower your rankings on SERPs.
- Don’t block link equity. Link-building is an important strategy for improving SEO, but it can only work if the link equity is transferred from one website to the other. If your robots.txt file or meta robots tags are created correctly the pages you want to boost traffic to will be elevated and the less desirable pages will fade into the background and likely go unnoticed.
Okay, let’s sum it all up.
You don’t have to use a robots.txt file or meta robots tags, but using them gives you more control over how web crawlers scan and index pages within your website. If you do choose to use a robots.txt file, you can easily create one on your own or use our free Robots Txt Generator.
Now, go impress your team with all your newfound knowledge and create the perfect robots.txt file for your website.

Subscribe to Our Blog
Stay up to date with the latest marketing, sales, service tips and news.
"*" indicates required fields