6 Common Onsite Mistakes That Hurt Your SEO Efforts
-

Aaron Gray
- Blogs
-

 May 31 , 2023
May 31 , 2023 -
 14 min read
14 min read
For many, the first thing that comes to mind about search engine optimisation (SEO) is content, and they aren’t wrong. The last major update to Google’s ever-growing-complicated algorithm have pressured websites to churn out more helpful content. The search engine can’t reiterate the need for ‘people-first content’ enough.
However, content quality is only a slice of the SEO meat pie. A quick look at Google Search Essentials will show that many guidelines focus on the technical side, from structuring sitemaps to debugging. The good news is that the guidelines say website owners usually need to do a few things and that their sites comply without them noticing.
The bad news is that such a sense of security tends to lead to mistakes that undermine a website’s SEO efforts. A study of 100,000 websites and 450 million web pages by SEMrush revealed that four of the top five onsite issues are considered the most severe. The study discovered moderate and severe issues in 96% of the sample size.
Because of this, you may want to view your website right now. It may be suffering from one or some of the most common on-page SEO issues.
- Duplicate content
 As sophisticated as the Google algorithm may seem, it still has its fair share of shortcomings. For instance, it can’t discern the original among multiple copies of the same content. It mostly won’t bother doing so, leading to reduced traffic for all copies. If it does bother, there’s a high risk of ranking the wrong version.
As sophisticated as the Google algorithm may seem, it still has its fair share of shortcomings. For instance, it can’t discern the original among multiple copies of the same content. It mostly won’t bother doing so, leading to reduced traffic for all copies. If it does bother, there’s a high risk of ranking the wrong version.
Contrary to popular belief, duplicate content is a regular occurrence. Although there are no hard or fast numbers on how prevalent it is, Matt Cutts estimated in 2013 that between 25% and 30% of all live content consists of duplicates. He added that most weren’t made to dupe the algorithm, so search engines typically leave them be.
According to Moz, duplicate content stems from three common causes. Naturally, websites that scrape or copy-paste content from other sites generate duplicates. This is more prevalent among product listings that lift information from the manufacturer word for word.
However, duplicates without malicious intent are often the result of URL variations, of which there are two kinds. The first is using URL parameters or the string of characters that follow a question mark at the end of a static URL.

In the example above, the static URL and the ones with parameters lead to the same page about widgets. The trouble with this is that search engines treat each URL separately, leading them to see duplicates. This results in keyword cannibalisation, where multiple URLs of the same page compete for search results supremacy.
The second is having separate versions of the same site, differentiated only by the HTTP/HTTPS and WWW prefixes. The ‘S’ in HTTPS indicates that the website is protected by data encryption but is more or less the same as its HTTP counterpart at face value. The same applies to WWW or a lack thereof, the latter being known as naked URLs.
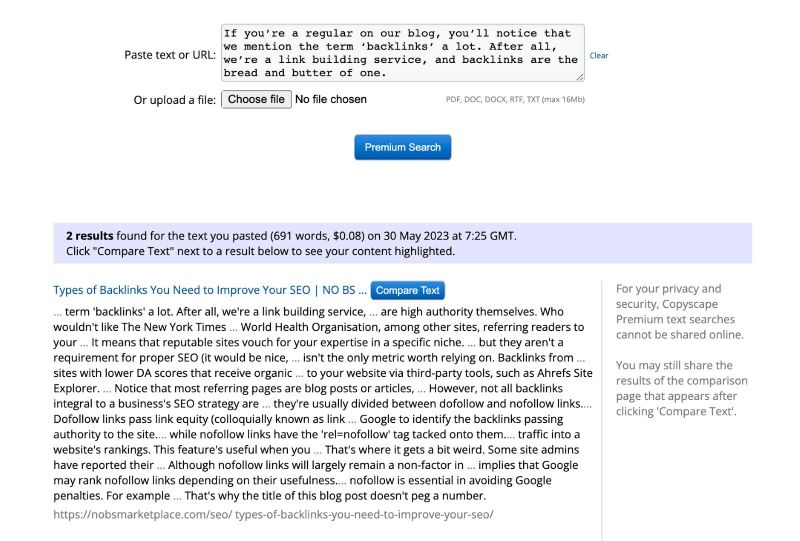
You can detect potential duplicates with SEO auditing tools, such as Ahrefs Site Audit. The tool reports the number of page clusters with a matching canonical tag and those without one. Here’s an example using the NO-BS Marketplace website.

As you can see, the tool picked up 22 near duplicates for one cluster. As it turns out, they come from the website’s blog page. As of this writing, the blog page runs for 21 pages, including the landing page. Duplicate number 22 is a copy of the landing page itself.

The difference is that the first URL has a canonical tag, allowing Googlebot to know which copy of the page to index and which to ignore. You can see its effects, as the canonical page has a far higher Page Rating (PR) than the one without.
Another acceptable method of managing duplicates is a 301 redirect, which experts recommend for handling the HTTPS and WWW dilemma. By redirecting duplicates to the primary page or site, they bring any inbound links they’ve earned as duplicates.
These methods are preferable over preventing crawlers from accessing duplicate content. Search engines need to see every page on the site to make a sound judgment when faced with duplicates. As mentioned earlier, Google neither rewards nor penalises duplicate content, but it’ll know something’s up when you try to hide them.
- No alt tags. Image search has grown cleverer through the years. It all began with a spike in demand to see Jennifer Lopez’s green Versace gown, which she wore at the Grammy Awards in 2000. Today, searching for “jennifer lopez green dress” is easy as pie for Google.
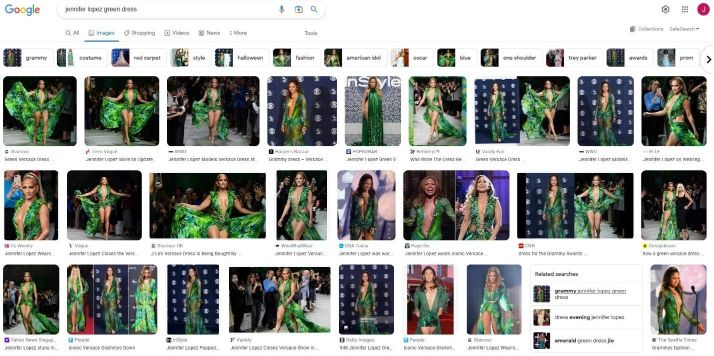
Despite this impressive accuracy, image search is still limited to what it sees compared to people. For starters, it will struggle to understand context, leading to image results that aren’t what the user has in mind. Until that day comes, the system will keep relying on tags in the code, namely alternative (alt text).
Primarily designed for accessibility, alt text describes images and their functions on the content. Screen readers represent images by reading their alt text for visually impaired users or those with a learning disability. It’s also useful for users who can’t load the images due to a technical glitch.
More importantly, alt text is indispensable for SEO. This doesn’t mean the alt text is a bunch of keywords (it’s considered keyword stuffing, and Google will promptly take action). Let’s take the image below as a short exercise.

Most software and online tools enable the easy addition of alt text into a website’s code. For the purposes of our example, here’s how it appears:
<img src=“burger with fries.jpg” alt=“burger with fries”>
The alt text above is acceptable, but it could be better. Experts have stressed the importance of making alt text as detailed as possible (without appearing too spammy), including the image’s context. Given that, a better alt text would be something like this:
<img src=“burger with fries.jpg” alt=“burger with fries on cutting board with ketchup and mustard”>
Being detailed about an image not only helps users with disabilities but also the website’s SEO. It adds more opportunities for the image to rank in different keywords, not just for searches of “burger with fries.” However, as most screen readers read only up to 125 characters, keeping alt text within that limit is crucial.
But if that’s the case, why are too many websites not doing this? Amid a clear consensus among SEO professionals, a few believe that alt text is only essential if a website wants its images to rank on image searches. Google Search Advocate John Mueller even specified that putting the text on the page is better than on the image, though he iterated that alt text must be descriptive.
Then again, if alt text doesn’t make sense for your SEO strategy, the least you can do is do it for users who can’t read content normally. It’s worth mentioning that roughly one in four people on Earth suffer from impaired vision. With this prevalence, it’s safe to say that some of your site’s visitors are among them.
- Broken links. Imagine finding the content for which you’ve been looking high and low on Google. But upon clicking the link, you get this instead:

Sucks, doesn’t it?
Unfortunately, broken links are commonplace on the internet, regardless of circumstance. An analysis of over 2 million websites by Ahrefs last year revealed that nearly 75% of links are lost, the majority caused by link rot.
Link rot occurs when a link no longer directs to a specific page because it has either moved or been deleted. Without a redirect or at least a heads-up to visitors as to what happened, broken links can be dangerous for a website. First, people perceive broken links as red flags, especially if there are too many.
But worse, competitors can capitalise on broken links. The Ahrefs study also shows an example featuring a website used as a reference for a U.S. Supreme Court case. The original page is no longer available, so someone swooped in and made this in its place:

Assuming either of those downsides doesn’t bother you, broken links are also bad for a website’s ‘crawl budget.’ Search engine crawlers crawl on multiple pages in a website but not all of them. A crawler’s time on a broken link could’ve been better allocated to crawling on a live one. As a result, the latter ends up taking the hit.
Stopping broken links from appearing is impossible because the internet is constantly changing, but there are ways to manage them. One is link reclamation, which employs a 301 redirect for the link to the new location. If the page has been removed, the link must lead to a substantially equivalent page or asset, which can be complicated.
Google advises against redirecting broken links to a website’s home page, which they refer to as a ‘soft 404.’ If visitors expect to see an article upon clicking a link, they’ll be left confused when they realise they’ve been led to the home page. Soft 404s also negatively affect the crawl budget.
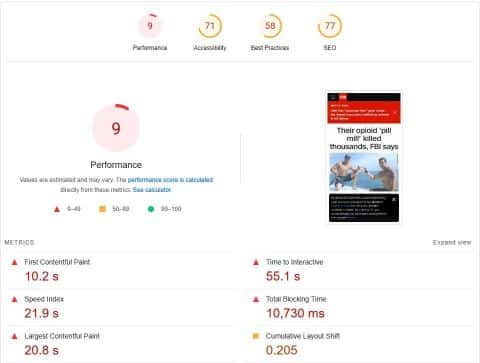
- Low code-to-text ratio. The code-to-text ratio, sometimes called text-to-HTML ratio, refers to the amount of code and visible text relative to each other. Most SEO professionals agree that the ideal number for this ranges between 25% and 70%, meaning a page or site should consist of 25% to 70% visible text. Some claim you can still get away with between 15% and 80%, but that’s already stretching it.As coding is complicated enough as it is, it’s no surprise that a low code-to-text ratio is one of the most common mistakes people make with on-page SEO. We ran several news websites on Google’s PageSpeed Insights, and here’s what we found, starting with CNN.com.
Meanwhile, the results below are from NYTimes.com.
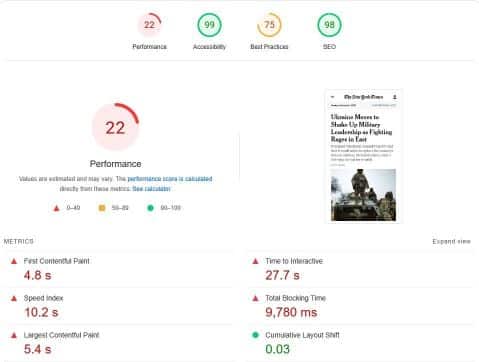
Note that both results pertain to the websites’ mobile versions, and for good reason. In the next few years, more people will access websites with their mobile devices, maybe surpassing those who do so via desktops and laptops.
As you can see, these examples have decent scores in every category but performance. You can check this post about what some of the parameters mean, but the fact that nearly every figure is in red doesn’t sit well.
Both instances share a major cause of such subpar performance: too much JavaScript. PageSpeed Insights reported that CNN.com has an opportunity to reduce loading time by nearly 14 seconds and NYTimes.com by almost 4 seconds if they remove scripts they don’t use. While some might argue it isn’t a big deal if users have high-speed data, assuming everyone has, is a mistake.
Moreover, while Google said that it doesn’t take a site’s code-to-text ratio into account in SEO (as it’s a matter of preference), a slow-loading website will affect SEO anyway. Taking too long to load a page is an excellent way to turn away visitors, which can drive its search ranking down.
A workaround many web designers employ involves progressive or lazy loading. The script may be hard at work in the background, but visitors only see a blank page while it works. Progressive loading ensures visitors that the site or page is functional by slowly introducing text and assets. Think of it as releasing a teaser, the trailer, and finally the full movie but within a few seconds.
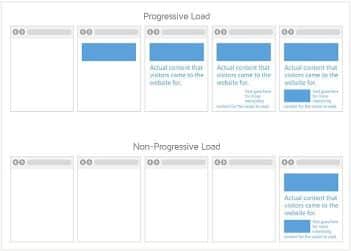
A visitor can elect to leave at any part of the loading process, likely missing out on the content as soon as it’s done loading. Consumer studies show that many people are less likely to return to the website after a few instances of a non-loading page.
- Too many internal links. If you’re a regular in the NO-BS blog, you may notice that many of my blog posts link to pages within the site, and this is no exception. Internal linking provides numerous benefits, from aiding visitors in going around the site to helping crawlers reach more pages.However, like many SEO practices, it’s easy to take internal linking too far. In an SEO hangout video in 2021, Mueller cautioned site owners against stuffing pages with excessive on-site links. He said the links risk confusing the crawlers, and they’ll be unable to determine the most crucial links to index. Such an arrangement will be, for lack of a better term, a giant mess.
He also stated the risk of diluting a link’s value. The entire page loses its structure, making the crawlers’ job of ranking a site’s pages harder. It isn’t a big deal if internal linking sends clear signals informing the search engine of the role of each link involved (e.g., blog post linking to the item category page). However, some setups can be a pain to untangle.
There’s no hard or fast maximum number of allowable on-site links. Cutts mentioned in his blog that he advised keeping under 100 links, but that was decades ago when Google could only index up to 100 kilobytes of a page.
Today, Google is far more capable of handling more data; you won’t even see that 100-link rule on the current guidelines anymore. Nevertheless, it’s still relevant in today’s SEO, mainly due to the need for quality user experience. A hundred links are too much for the average user to track, let alone click one by one.
Fortunately, internal link building more or less follows the same rules as external link building. It all boils down to the quality of the linking page and the ideal keywords. If done correctly, a page may receive link equity from supporting links.

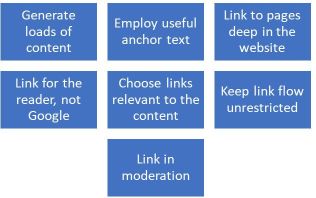
SEO guru Neil Patel shares his seven commandments of internal link building. You can check them out on this page to get down into the weeds, but the gist is the following:
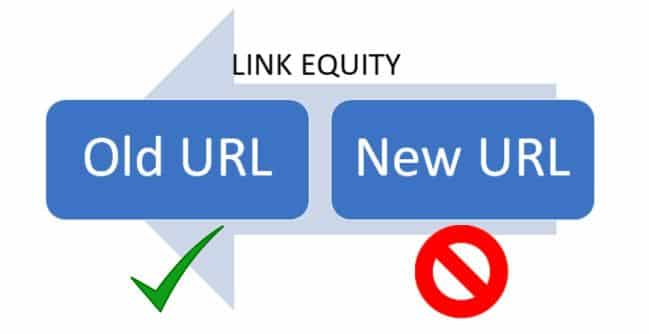
- Misuse of redirects. Earlier, I explained the importance of a 301 redirect for managing duplicate content and broken links. But even here, there’s a bit of confusion.A 301 is a permanent redirect, meaning that the site owner intends to lead visitors to a new page as the old one is no longer being updated. Meanwhile, a 302 is a temporary redirect, which a site owner can use to lead visitors to a limited-time promo page or conduct A/B testing.
There’s a world of difference separating these two kinds of redirects—and it isn’t just the term. In SEO, a 301 redirect signals search engines to deindex the old page and crawl on the new one. Any link equity the old page has acquired over its service will be passed onto the new one.

Google sometimes corrects accidental 302 redirects to 301s, but relying on it to do the job isn’t optimal. Many site owners aren’t aware that they’re missing out on significant SEO benefits by treating 302s as permanent. It pays to know what your new page will be used for before enacting a redirect.
Final thoughts
These on-page SEO issues are nothing to be ashamed of, as SEO’s fluid nature means it changes more often than expected. I can say from experience that I’m still learning the ups and downs of SEO practices, and there’s always the risk of a major update rendering everything I know up to this point obsolete.
That said, doing nothing to resolve these issues is shooting yourself in the foot. Nobody knows how the industry will change in the next couple of years, which is why correcting these issues as early as now is critical. If you need expert help, don’t hesitate to give NO-BS Marketplace a call or visit this page to learn how our in-house team works.
Subscribe to Our Blog
Stay up to date with the latest marketing, sales, service tips and news.
