AI Scraping is Putting Content Creation in a Pickle
-

Jonas Trinidad
- Blogs
-

 August 19 , 2025
August 19 , 2025 -
 9 min read
9 min read
Allow me to start today’s topic by defining a term: Catch-22.
American author Joseph Heller coined the term in his eponymous book, Catch-22. It refers to a situation in which the only viable solutions aren’t great. His example features a soldier looking to get out of combat duty. Showing concern for their safety in the line of duty shows that they’re thinking straight, meaning they can’t be discharged on grounds of insanity.
Or what about that meme where “you need experience to get experience?” You’re fresh out of college and in search of a job to gain experience, but companies don’t pick you because you lack experience. There are workarounds, but that isn’t what we’re talking about today.
As explained in my post about SEO’s role in preventing AI model collapse, AI models need lots of quality training data. Chatbots, writing tools, image generators—all these and more rely on existing content to do what they’re designed for.
But in the past few days, content creators and publishers have expressed concern about AI “scraping” their content. Reddit announced that it would block the Wayback Machine from archiving its content except for the homepage. Speaking to The Verge, spokesperson Tim Rathschmidt said the move was made amid privacy concerns.
“Fair enough, let’s find an alternative,” you might think. Technically, there’s another viable source. But as you’ll learn later, that isn’t any better.
How Scraping Works
In her book Web Scraping with Python, software engineer Ryan Mitchell (not to be confused with the mountaineer or actor) defines web scraping as collecting data via any means other than visiting a website yourself. It involves creating an automated program that queries the site’s server, sends a request, and parses the data for extraction.
Mitchell adds that web scraping goes beyond accessing a site or page. A scraping program can go through countless databases, equivalent to millions of pages, at a time. As a result, when you ask an AI-assisted tool for “cheap flights to Boston,” it provides the lowest rates from multiple carriers and even recommends the best time to buy the ticket. (1)
Scraping for AI models is poised for a major boom over the decade. One forecast by Future Market Insights predicts the market value to almost quintuple, from USD$886.03 million in 2025 to USD$4.37 billion in 2035. To hardly anyone’s surprise, increased investment in AI among businesses is seen as the main driver. (2)
The Privacy Dilemma
Reddit’s recent decision may as well be grounded in history. As it turns out, we’ve been dealing with privacy concerns since scraping became a thing.
OpenAI’s GPT line of AI models is notorious for its exponential rate of data consumption. The chart below shows how much data each GPT model has consumed for its training.
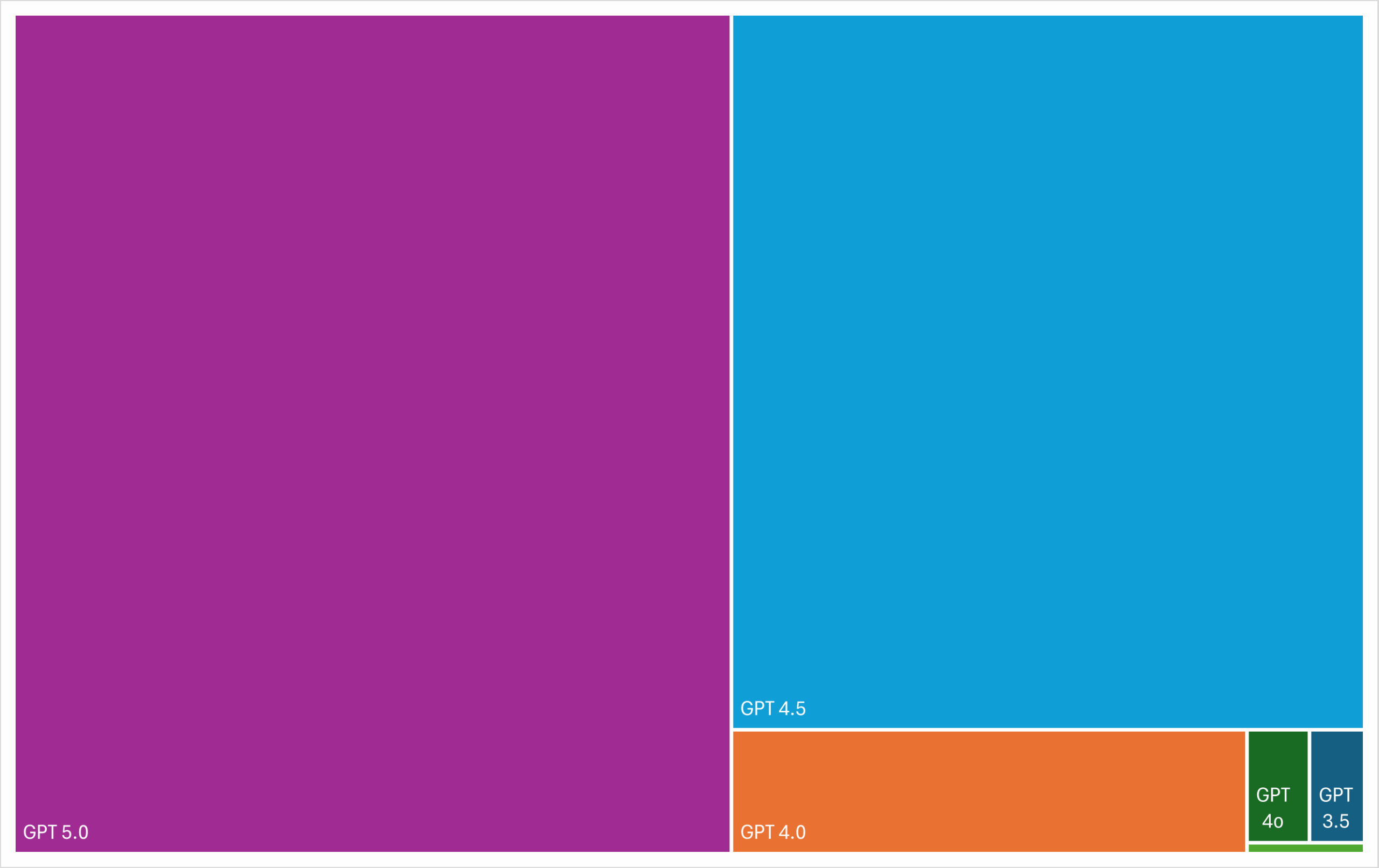
The later models dwarf their predecessors so much that they’re barely visible here. While the total parameter count for GPT 5.0 has yet to be publicly disclosed, it’s estimated to be almost 150,000 times more than what was used for developing GPT 1.0. It’s impossible to create state-of-the-art models in a short timeframe without scraping.
However, as innocent as gathering information on the Web may seem, a large portion of it consists of personal data. This data, ranging from profile pictures to personal opinions, is fair game in a model’s eyes, especially if it’ll be used for public benefit. Yet, convincing the public that scraping is a good thing is quite an ask.
As an example, look no further than Clearwater AI’s facial recognition system. Its AI model was designed to help law enforcement agencies identify criminals regardless of the photo or video quality. The company operated in secret until New York Times journalist Kashmir Hill revealed its existence in 2020, including how it trained its model.
Hill’s deep dive into the code revealed that it would be incorporated into augmented reality glasses. All the wearer needed to do was train their gaze on any individual, after which the glasses would display the latter’s info. Clearwater’s facial database, Hill reported, totaled over three billion scraped from various social media platforms and websites.
The potential for misuse was all too clear. Soon, Clearwater faced a class-action lawsuit, and governments around the world enacted policies in response. In June 2024, it agreed to a settlement that involved giving those whose faces are in the database a 23% stake in the company, valued at around USD$52 million at the time. (3)
Despite the danger, legal experts say that scraping continues unabated because of its legal status. One paper described it as existing in a “weird ethical twilight” viewed through two opposing lenses. Some argue that it’s fair game because the data is already on the public Web, whereas others insist that property lines should still be respected. (4)
The Alternative
If web scraping becomes prohibited, is AI model building still possible? Technically, yes.
While scraping is currently widespread, some firms such as Google and Meta train their models using synthetic data. It shares the same properties as its real-world counterpart but without the personal information. A financial or medical record may be replicated, down to the exact individual values, but it doesn’t replicate the record owner’s details.
Synthetic data is poised to be the norm, as recent studies conclude that model building is quickly running out of real-world data. AI analytics firm Epoch predicted that the supply of available human text data will only last between 2026 and 2032 at the rate AI models are consuming data. Overtraining can exhaust that supply much faster. (5)
So, problem solved, right? Well, not quite.
For all the credit we give to AI for being sophisticated, it is far from the utopian technology we expect it to be. There has yet to be a model that can fully grasp and imitate key aspects of human intelligence, namely creativity and nuance. We can’t even keep generative AI from creating one too many fingers or limbs!

I didn’t even generate this. I got it from a stock image site.
Now, imagine current AI models being trained on purely synthetic data. Because the data is created based on real-world data and not directly from real-world conditions, the model tends to “hallucinate” or generate outputs that aren’t grounded in reality. To paraphrase Adam Savage’s iconic Mythbusters quote, the model “rejects reality and substitutes its own.”
Contrary to popular belief, hallucination isn’t necessarily bad. Data scientists say that all AI-generated results are a form of hallucination, but those made using synthetic training data are far more outrageous. Combined with the fact that the hallucination rate goes up with a model’s accuracy, you can see why relying solely on synthetic data isn’t ideal. (6)
The table below shows the accuracy and hallucination rates (H%) of OpenAI’s o-series GPT models. The data is from a study the company conducted last April, which coincided with the release of the GPT o4-mini.
| Model | Release Date | SimpleQA | PersonQA | ||
| Accuracy | H% | Accuracy | H% | ||
| GPT o3 | January 2025 | 0.49 | 0.51 | 0.59 | 0.33 |
| GPT o4-mini | April 2025 | 0.20 | 0.79 | 0.36 | 0.48 |
| GPT o1 | December 2024 | 0.47 | 0.44 | 0.47 | 0.16 |
Source: OpenAI
The Pickle (and How to Eat It)
Now that we’ve put the intricacies of AI out of the way, let’s get all our ducks in a row. If you’re like me, who doesn’t rely on AI to create content, you’re fine. In fact, this caliber of content creation may soon be needed to supplement the growing scarcity of quality data.
If you’re among the majority who need AI tools to produce content, the current situation complicates things. With platforms and publishers fighting back against AI infringing on their intellectual properties, future models might be trained on less real-world data and more on synthetic data.
Sure, you can argue that Google doesn’t care whether a human or an AI tool created the content. Gary Illyes said so himself in an interview during the recent Search Central Live. However, on that same interview, he also said this:
“I don’t think that we are going to change our guidelines anytime soon about whether you need to review it or not. So basically, when we say that it’s human, I think the word “human-created” is wrong. Basically, it should be “human-curated.” So basically, someone had some editorial oversight over the content and validated that it’s actually correct and accurate.”
The biggest mistake anyone can make in this case is leaving the entire content creation process to AI. I can’t stress this enough, but AI should augment processes, not replace them entirely. Human oversight is still a must, especially if you produce YMYL content.
Think of it this way: you’ve just been promoted to editor, and AI is the newly hired writer. Don’t let that promotion go to waste. I know I won’t.
References
1. Mitchell R. Web Scraping with Python [Internet]. O’Reilly Media Inc.; 2018 [cited 2025 Aug 13]. Available from: https://edu.anarcho-copy.org/Programming%20Languages/Python/Web%20Scraping%20with%20Python,%202nd%20Edition.pdf
2. Future Market Insights. AI-driven Web Scraping Market Analysis – Growth & Forecast 2025 to 2035 [Internet]. Futuremarketinsights.com. 2025 [cited 2025 Aug 13]. Available from: https://www.futuremarketinsights.com/reports/ai-driven-web-scraping-market
3. Hill K. Clearview AI Used Your Face. Now You May Get a Stake in the Company. The New York Times [Internet]. 2024 Jun 14; Available from: https://www.nytimes.com/2024/06/13/business/clearview-ai-facial-recognition-settlement.html
4. Solove D, Hartzog W. The Great Scrape: The Clash Between Scraping and Privacy The Great Scrape: The Clash Between Scraping and Privacy [Internet]. Scholarly Commons at Boston University School of Law. Boston University School of Law; 2024 [cited 2025 Aug 13]. Available from: https://scholarship.law.bu.edu/cgi/viewcontent.cgi?article=4885&context=faculty_scholarship
5. Villalobos P, Sevilla J, Heim L, Besiroglu T, Hobbhahn M, Ho A. Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning [Internet]. Available from: https://arxiv.org/pdf/2211.04325
6.Moore-Colyer R. AI hallucinates more frequently as it gets more advanced — is there any way to stop it from happening, and should we even try? [Internet]. Live Science. 2025. Available from: https://www.livescience.com/technology/artificial-intelligence/ai-hallucinates-more-frequently-as-it-gets-more-advanced-is-there-any-way-to-stop-it-from-happening-and-should-we-even-try
Subscribe to Our Blog
Stay up to date with the latest marketing, sales, service tips and news.
Sign Up
"*" indicates required fields
