
If you’ve been closely following the rise of AI tools, one company seems to be getting most of the attention: Perplexity. Currently valued at roughly USD$20 billion, this San Francisco-based startup has made waves in the AI scene since its founding in 2022.
Not because of its large language model (LLM). Not because of its growing valuation.
It’s positioning itself to be the next Google.
Its recent attempt to buy Chrome for USD$34.5 billion isn’t beating the allegations. While some analysts dismissed it as a stunt amid a likely breakup of the Big G, having a proving ground for developing AI habits like Chrome would be a significant boost for Perplexity. The technology transfer would also give its own browser, Comet, a considerable edge.
Explaining the economics of mergers is beyond my pay grade, but it got me thinking. With all the talk about how search engines are changing in the AI era, Perplexity may be on the road to becoming one. If it does, then it won’t be unusual if other LLMs follow suit.
Explaining LLMs Like You’re Five
I’ve used the term “LLM” quite a couple of times, but I haven’t had the chance to explain it. Fortunately, now’s a perfect time to understand it down to its nuts and bolts, starting with the term “language model.”
Google defines a language model as a type of machine learning model designed to predict the next word or set of words. If that rings a bell, that’s because Google’s autocomplete is one example of a language model. It predicts the words the user will likely enter next based on searches they and other users have made in the past. (1)
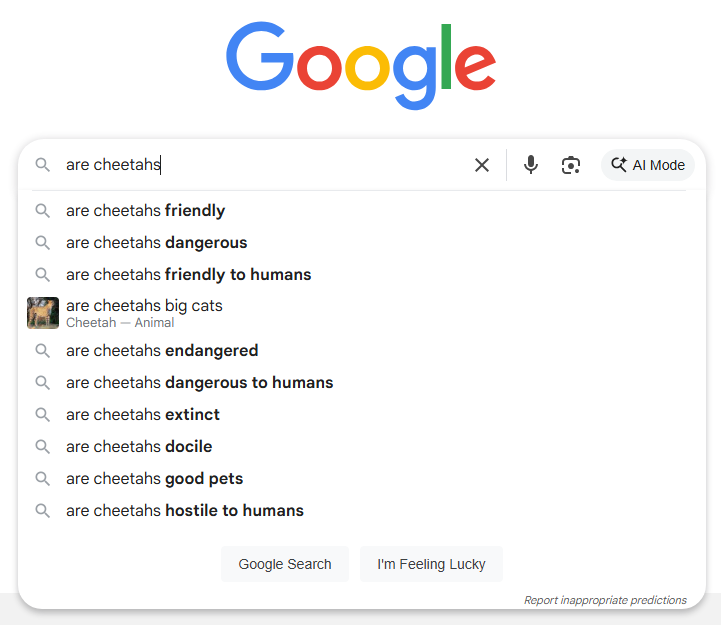
Training a language model requires feeding it “tokens.” These building blocks of AI training help the model understand each word it receives by breaking a sentence down into units, typically per word. In this case, the query “are cheetahs friendly” consists of three tokens.
Do this millions or billions of times, and a language model evolves into an LLM. There’s no widely accepted minimum, but most LLMs today are trained on at least two billion training parameters. BERT, released in 2018, is considered an LLM despite only being trained using around 110 million parameters. (1)(2)
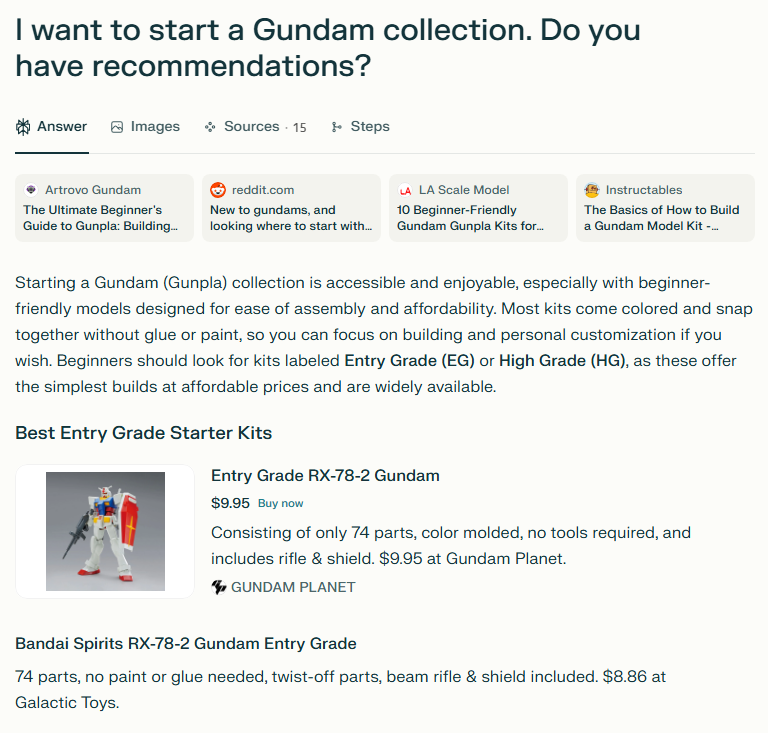
Their large size enables them to respond to more complex queries and perform a variety of tasks. That’s how AI tools like Perplexity manage to deliver detailed information on, say, a beginner’s guide to starting a Gundam collection. And it comes with a few links, too.
Is Perplexity a Search Engine?
Going by the company’s words, Perplexity is described as an AI-powered search engine. It also described the tool as an answer engine, but the source for that is several months old. You can be one or the other, but not both. (3)
Let me put it this way.
SEARCH ENGINESanswer with search | ANSWER ENGINESsearch for answers |
Somewhat tongue-in-cheek, but the two are distinct even if AI is blurring the line dividing them. Search engines return a list of links to pages relevant to a user’s query; the iconic “blue links” as professionals call them. Meanwhile, answer engines return a summary of the information users require, which saves time.
By this definition, Perplexity and similar tools are still acting like answer engines. They may provide a list of links, but the fact that they’re separate from the actual answer means not everyone may come across it. They aren’t like Google, which still provides apparent links to sources even when the results come with AI-generated summaries.
This may not look like a cause for concern, but it is. For starters, Perplexity isn’t foolproof.
I asked the tool who won the 1998 Autumn Tenno Sho, a Grade-1 horse race in Japan. The answer looks convincing…
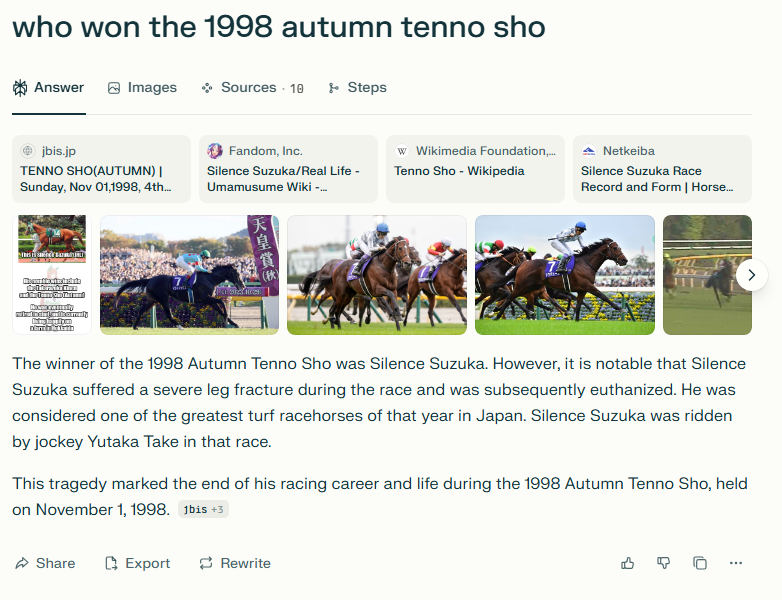
…except that it got one thing wrong.
Perplexity may have gotten the injury and euthanasia part right, but Silence Suzuka never finished the race due to said injury and had to be put down on the track. Maybe the tool was thinking about who won the hearts of everyone in that race, but that wasn’t what my query was asking. (4)
Other users have also reported that Perplexity returned inaccurate answers. Chris Dunlop, CEO of AI strategy firm Cub Digital, did a similar but more comprehensive experiment that involved asking the number of games New Zealand’s national rugby team have played in Dunedin since 1990. Then, he had the tool tabulate every game.
Despite Perplexity initially answering that the team played 20 games, the subsequent table returned 32. And one of them, against Australia, got the date and place wrong. He then ran 100 more sports and non-sports-related queries, resulting in an 85% accuracy rate.
Not bad, you say?
Well, Dunlop pointed out that this is more dangerous than having, say, a 50% accuracy rate. People are more likely to trust whatever comes out of Perplexity’s (or any AI tool’s) algorithm, including the 15% that’s completely wrong. (5)
This tendency, known as automation bias, is a major issue in treating Perplexity or a similar tool like a search engine. Without features that make double-checking easier, the tool risks not inspiring action, making users follow incorrect instructions, or even inflicting harm. (6)
Are LLMs Becoming Search Engines?
No. At least, not in their current state.
First, the earlier wrong answers that Perplexity returned are a side effect of hallucination. This is inevitable because LLMs are designed to generate probabilities based on the data provided. It’s up to the user to determine which of these probabilities is fact. At the same time, it’s also necessary to allow answer engines to create information.
That said, hallucination becomes a problem when it must process Your Money, Your Life (YMYL) queries. In November last year, a lawyer in Texas was fined for submitting a court filing that contained citations and quotes fabricated by AI. It was one of a string of cases that courts across the country dealt with that year.
It doesn’t help that there’s no way to understand how LLMs make decisions and why they make them. Worse, OpenAI’s study last April discovered that more advanced LLMs were more likely to hallucinate, and experts can’t explain why. (7)
There’s also the problem of the declining supply of good training data. Recent projections place the current data supply up to 2032 at the latest, but practices such as overtraining can hasten the decline by around five years.
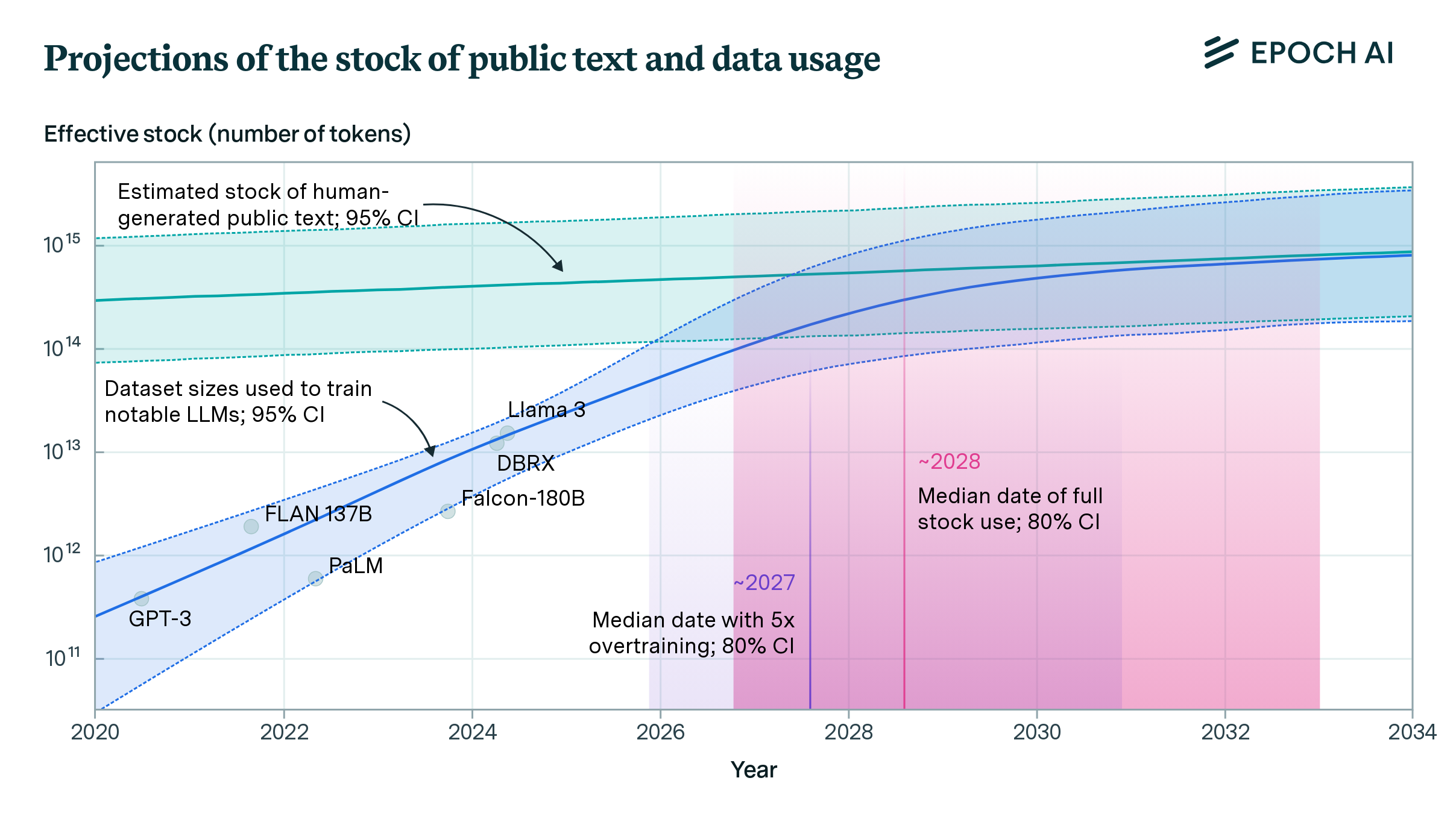
Source: Epoch AI
In light of this, AI companies and tech firms are turning to synthetic data. But as I explained in my post about the risk of model collapse, poor-quality synthetic data risks future models growing more inept with each iteration. Perplexity’s erroneous answers from earlier give a glimpse of what can happen if data quality can’t be guaranteed.
Lastly, LLMs are limited by their knowledge cutoff or the date of the latest data they were trained on. If you ask something current to a model whose cutoff date is up to last year, it should inform you that it can’t provide a reliable answer. Below is a list of verified cutoff dates for specific models.
| Developer | LLM | Cutoff Date | Source |
| OpenAI | GPT-4 | April 2023 | [a] |
| GPT-4o | October 2023 | [b] | |
| GPT-4.1 | June 2024 | [c] | |
| GPT-5 | September 2024 | [d] | |
| GPT-5 mini | May 2024 | [e] | |
| GPT-5 nano | May 2024 | [f] | |
| Anthropic | Claude Opus 4 | March 2025* | [g] |
| Claude Sonnet 4 | March 2025* | ||
| Claude 3.7 Sonnet | October 2024 | ||
| Google
Abbreviations: NA – Native Audio IP – Image Preview PTTS – Preview Text-to-Speech PIG – Preview Image Generation | Gemini 2.5 Pro | January 2025 | [h] |
| Gemini 2.5 Flash | January 2025 | ||
| Gemini 2.5 Flash-Lite | January 2025 | ||
| Gemini 2.5 Flash Live | January 2025 | ||
| Gemini 2.5 Flash NA | January 2025 | ||
| Gemini 2.5 Flash IP | June 2025 | ||
| Gemini 2.5 Flash PTTS | May 2025 | ||
| Gemini 2.5 Pro PTTS | May 2025 | ||
| Gemini 2.0 Flash | August 2024 | ||
| Gemini 2.0 Flash PIG | August 2024 | ||
| Gemini 2.0 Flash-Lite | August 2024 | ||
| Gemini 2.0 Flash Live | August 2024 | ||
| Gemini 1.5 Flash | September 2024** | ||
| Gemini 1.5 Flash-8B | October 2024** | ||
| Gemini 1.5 Pro | September 2024** |
*Reliable cutoff date is up to January 2025
**Deprecation started in September 2025
The downside is that an LLM’s answer is only as good as its latest training data, compared to search engines that constantly update in real time. As a workaround, some models now come with web browsing capability to retrieve and be trained on later data. This works by integrating search engines like Google for Gemini and Bing for OpenAI.
Perplexity is capable of web browsing, which is why it doesn’t have a published cutoff date. That said, it isn’t without risks, one of which is the possibility of the model leaking sensitive data and leading to a potential breach. Additionally, the tool may still not be able to access paywalled content (e.g., academic journals, subscription news services). (8)(9)
A Future Possibility
Just because it isn’t possible now doesn’t mean it won’t be a reality soon. If future models can somehow mitigate the issues explained and design an AI tool that encourages users to double-check the generated answers, they’ll be on the path to becoming search engines.
We’ve already started blurring the line dividing search and answer engines. From this point on, the only way is forward.
References
1. Google. Introduction to Large Language Models | Machine Learning [Internet]. Google for Developers. 2023. Available from: https://developers.google.com/machine-learning/resources/intro-llms
2. Understand LLM sizes [Internet]. web.dev. 2024. Available from: https://web.dev/articles/llm-sizes
3. What is an answer engine, and how does Perplexity work as one? | Perplexity Help Center [Internet]. Perplexity.ai. 2025 [cited 2025 Aug 29]. Available from: https://www.perplexity.ai/help-center/en/articles/10354917-what-is-an-answer-engine-and-how-does-perplexity-work-as-one
4. Japan Greatest Horses. Tragedy at the 4th corner - Silence Suzuka(サイレンススズカ), [Internet]. YouTube. 2021 [cited 2025 Sep 1]. Available from: https://www.youtube.com/watch?v=507PWyazGYY
5. Dunlop, C. Beware: Perplexity is Worse Than Wrong — It Tricks You Into Thinking It’s Right [Internet]. Medium. Realworld AI Use Cases; 2025 [cited 2025 Sep 1]. Available from: https://medium.com/realworld-ai-use-cases/beware-perplexity-is-worse-than-wrong-it-tricks-you-into-thinking-its-right-4e3e8f41920c
6. Kahn L, Probasco E, Kinoshita R. Issue Brief AI Safety and Automation Bias The Downside of Human-in-the-Loop AI Safety and Automation Bias The Downside of Human-in-the-Loop [Internet]. 2024. Available from: https://cset.georgetown.edu/wp-content/uploads/CSET-AI-Safety-and-Automation-Bias.pdf
7. Moore-Colyer R. AI hallucinates more frequently as it gets more advanced — is there any way to stop it from happening, and should we even try? [Internet]. Live Science. 2025. Available from: https://www.livescience.com/technology/artificial-intelligence/ai-hallucinates-more-frequently-as-it-gets-more-advanced-is-there-any-way-to-stop-it-from-happening-and-should-we-even-try
8. Cohen E. Hidden Dangers of LLM Web Browsing Technologies [Internet]. Medium. 2023 [cited 2025 Sep 1]. Available from: https://medium.com/@eilonc/hidden-dangers-of-llm-web-browsing-technologies-b786a5712b2b
9. Kiss R. Understanding Knowledge Cut-offs in GenAI Models [Internet]. PROMPTREVOLUTION. 2025 [cited 2025 Sep 1]. Available from: https://promptrevolution.poltextlab.com/understanding-knowledge-cut-offs-in-genai-models/